12 Visualización y Análisis de Datos
Hay tres sistemas principales de graficación en R, el sistema de graficación base, el paquete de lattice y el paquete ggplot2.
¡ATENCIÓN!
Antes de hablar del paquete con el qué graficaremos tenemos que hablar del mundo de tidyverse (hablaremos someramente, ya que es un paquete súper complejo que literal requiere un curso completo para hablar de él ✨)
12.1 🔍¿Qué es tidyverse?
Es una colección de paquetes de R con una filosofía de diseño predefinida, diseñada para la manipulación y visualización en ciencia de datos. Todos los paquetes comparten una filosofía de diseño, gramática y estructura de datos.
Instala el paquete tidyverse completo con:
Paquetes escenciales:
ggplot2→ gráficardplyr→ Manipulación de datostidyr→ ordenar datosreadr→ leer datostibble→ dataframes modernosstringr/forcats→ texto y factores
12.2 ⭐️Introducción a ggplot2
ggplot2 es un paquete de R súper efectivo para crear gráficos de calidad para publicación y se basa en la gramática de los gráficos, la idea de que cualquier gráfico se puede construir a partir del mismo conjunto de componentes: un conjunto de datos, la estética de mapeo y capas gráficas:
Los conjuntos de datos son los datos que nostros, los usuario, proporcionamos.
La estética de mapeo es lo que conecta los datos con los gráficos. Le decimos a ggplot2 cómo usar los datos para afectar el aspecto del gráfico, para cambiar lo que se traza en el eje X o Y, o el tamaño o color de diferentes puntos de datos.
Las capas son la salida gráfica real de ggplot2. Las capas determinan qué tipos de trama se muestran (plot de dispersión, histograma, etc.), el sistema de coordenadas utilizado (rectangular, polar, otros) y otros aspectos importantes del gráfico.
12.2.1 En resumen
ggplot2 es un paquete de R que sirve para hacer gráficos estéticos, claros y profesionales para publicación con muy poco código.
Lo que hace especial a ggplot2 es que construye los gráficos por partes, como si armaras un “sándwich”, es decir te permite construir gráficos por capas:
datos → estética → geometría → tema → etiquetas.
Esto permite que:
Tus gráficos sean fáciles de leer y de hacer.
Modificar elementos y que está acción no destruya todo el gráfico.

- Poder adaptar cualquier visualización biológica (expresión, abundancia, etc.)
Cargamos la libreria con:
12.3 🧩 Los 5 bloques de la Gramática en ggplot2
- Datos
(data)
El conjunto de datos que quieres graficar.
{r}
#Cargamos el data y definimos la variable
hp_data <- read.csv("hp_data/Characters.csv", sep = ";")
- Estética
(aes = aesthetics)Indica qué variable va al eje X, al Y, al color, tamaño, etc.
{r}
#Indicamos las variables
aes(x = Birth, y = Gender, color = House)
- Geometría
(geom)
Corresponde a el tipo de gráfico:
geom_point()→ puntosgeom_histogram()→ histogramasgeom_boxplot()→ boxplotsgeom_bar()→ barras
AQUí DEJAMOS ESTE LINK QUE TE PERMITIRÁ CONOCER TODOS LOS PLOTS QUE PUEDES REALIZAR CON LA PAQUETERIA ggplot2.
- Escalas
(scale_)
Permite ajustar los colores, tamaños, ejes, etc.
{r}
#Definimos la paleta de colores
hp_cols <- c( "Gryffindor" = "#b30000", # rojo intenso "Slytherin" = "#005f2f", # verde fuerte "Ravenclaw" = "#002b80", # azul profundo "Hufflepuff" = "#e6b800", # amarillo dorado "Beauxbatons Academy of Magic" = "#6ea8ff", # azul claro elegante "Durmstrang Institute" = "#660000" # burdeos oscuro )
#Ajustamos los colores
scale_fill_manual(values = hp_cols)
- Temas
(theme)
Aspecto final del gráfico: fondo, líneas, letras.
{r}
theme_minimal()
12.4 🎨 Ejemplo explicado paso a paso
{r}
#Ahora juntamos todo lo aprendido!
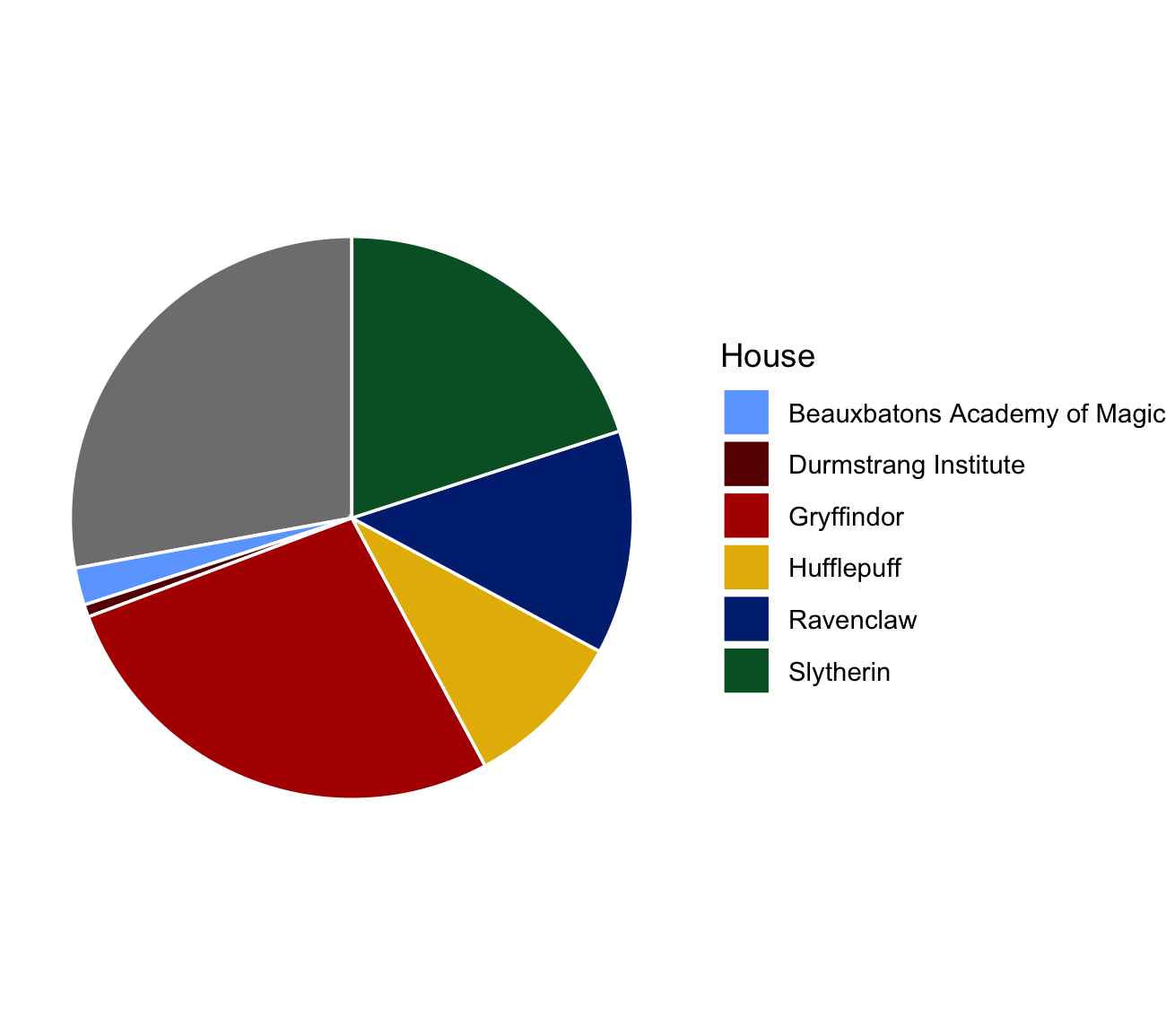
hp_data %>% count(House) %>% ggplot(aes(x = 2, y = n, fill = House)) + geom_col(width = 1, color = "white") + coord_polar(theta = "y") + scale_fill_manual(values = hp_cols) + xlim(1.5, 2.5) +``labs(title = "Casas de Hogwarts") +theme_minimal()
13 Estadística Descriptiva en R
La estadística descriptiva permite resumir y entender rápidamente las características principales de un conjunto de datos. En esta sección cubriremos los conceptos esenciales:
- Media
- Mediana
- Desviación estándar
- Resumen de datos
13.1 🧠 Conceptos Básicos
13.1.1 🔸 Media
La media es simplemente el promedio de los datos.
👉 Tomas todos los valores, los sumas y los divides entre la cantidad de datos.
Ejemplo:
Datos: 4, 6, 10
Media = (4 + 6 + 10) / 3 = 6.67

13.1.2 🔸 Mediana
Ejemplo:
Datos: 2, 8, 5 → ordenados: 2, 5, 8
Mediana = 5
Si hay números pares, no hay un valor justo al centro, así que tomas los dos del centro y sacas su promedio.
Ejemplo:
Datos: 1, 3, 7, 10 → del centro: 3 y 7 → mediana = (3+7)/2 = 5
La mediana sirve mucho cuando hay valores extremos (outliers) que podrían afectar la media.
13.1.3 🔸 Desviación Estándar
Es una medida que indica qué tan dispersos o separados están los datos respecto a la media.
Si la desviación estándar es pequeña, los valores están muy cerca del promedio.
Si es grande, los valores están muy separados y hay más variabilidad.

13.1.4 🔸 Resumen de datos
Incluye:
- Mínimo: Es el valor más pequeño del conjunto de datos, Ayuda a saber cuál es el extremo más bajo.
- 1er cuartil (Q1) : Es el valor qué marca el 25% de los datos inferiores cuando están ordenados.
Es decir:
25% de los datos están por debajo de Q1
75% están por encima
Q1 ayuda a saber dónde empieza la parte “baja” de los datos.
- Mediana: Es el valor que divide los datos en dos partes iguales (50%).
(Es muy útil cuando hay valores extremos porque no se altera tanto como la media).
- Media: El promedio de los datos (Se usa para representar el “centro”, pero es sensible a valores extremos).
- 3er cuartil (Q3): Es el valor que marca el 75% de los datos ordenados.
Significa:
75% de los datos están por debajo
25% por encima
Ayuda a ver dónde empieza la parte “alta” de los datos.
- Máximo: Es el valor más grande del conjunto.
13.2 📥 1. Cargar datos en R
Usaremos un vector de ejemplo llamado x:
x <- c(5, 8, 12, 4, 6, 9, 10, 7)13.3 📐 2. Calcular medidas básicas
13.3.1 Media
mean(x)13.3.2 Mediana
median(x)13.3.3 Desviación estándar
sd(x)13.3.4 📦 3. Resumen de datos
R ofrece una función integrada:
summary(x)Esto muestra: - Mínimo - Q1 - Mediana - Media - Q3 - Máximo
13.4 📊 4. Visualización básica
Para complementar la estadística descriptiva, podemos usar un histograma:
hist(x, main = "Histograma de valores", xlab = "Valores", col = "lightpink")Y un boxplot:
boxplot(x, main = "Boxplot de valores", col = "lightblue")13.5 🧪 5. Ejemplo completo
x <- c(5, 8, 12, 4, 6, 9, 10, 7)
media <- mean(x)
mediana <- median(x)
desv <- sd(x)
resumen <- summary(x)
cat("Media:", media, "\n")
cat("Mediana:", mediana, "\n")
cat("Desviación Estándar:", desv, "\n")
cat("\nResumen:\n")
print(resumen)- La estadística descriptiva permite obtener una visión general rápida de los datos.
- R facilita estos cálculos con funciones simples e intuitivas.
- Estas herramientas son la base para análisis más avanzados en genómica y ciencias de datos.
13.5.1 Referencias
- The Carpentries. (2025). R for Reproducible Scientific Analysis.
https://swcarpentry.github.io/r-novice-gapminder/08-plot-ggplot2.html - Demiryürek, G. (2021). Harry Potter Dataset. Kaggle.
https://www.kaggle.com/datasets/gulsahdemiryurek/harry-potter-dataset - Montgomery, D. C., & Runger, G. C. (2014). Applied Statistics and Probability for Engineers.
- Crawley, M. J. (2015). Statistics: An Introduction Using R.
- Wickham, H., & Grolemund, G. (2016). R for Data Science.